search overview
overview
provide a peer-to-peer search engine that decentralizes content crawling and storage, search result rankings, and economics.
problem
the dominant search engine began with no capital resources and the idea that content on the internet could be indexed with weighting of credibility. the weighting was established by the quantity and quality of sources that referenced the content. the experience from that cheap and easy method was good enough to immediately dominate the market, and is still adequate.
since then, established search engines have applied money and talent to incrementally improve the personalization, context and predictiveness of the results. the cost of these incremental improvements is required to maintain domination in the market, but is subject to diminishing margins of return. crawling the internet in bulk from a centralized data center is capital intensive and requires evading IP address blocking. the resources required to centralize the processing and storage of the search indexes is prohibitive.
a decentralized search engine will be slower and produce less nuanced results than a centralized search engine that has inference and bias applied to the raw content.
solution
first, manage expectations of what a decentralized search engine can do. the performance and accuracy of a decentralized search engine won't match the current state in the search engine industry. that said, the performance of search engines from 20 years ago, prior to artificial intelligence, speech and image recognition, and multi-million server data farms is still adequate for many searches.
the proposed decentralized search engine won't compete well against current market state, but the performance potential of this proposed solution improves as Moore's law doubles disk, processor and network speed, and Metcalfe's law improves with participants on the network.
the availability of content and search results presented without bias combined with an economic incentive model for participants has to be considered as compensation for the feature and experience gap between the initial (adequate) search engine and the current market state.
all aspects of trust and centralization will disappear across all of society's activities. the emerging generation of internet users don't value content endorsed by a prestigious university like previous generations did. they value distributed votes of confidence from their peers. a decentralized search engine will be solved at some point when Moore's law makes it obvious. this proposal suggests how to begin solving it now.
a decentralized search engine can add free computing power faster than a centralized search engine can add computing power at great cost.
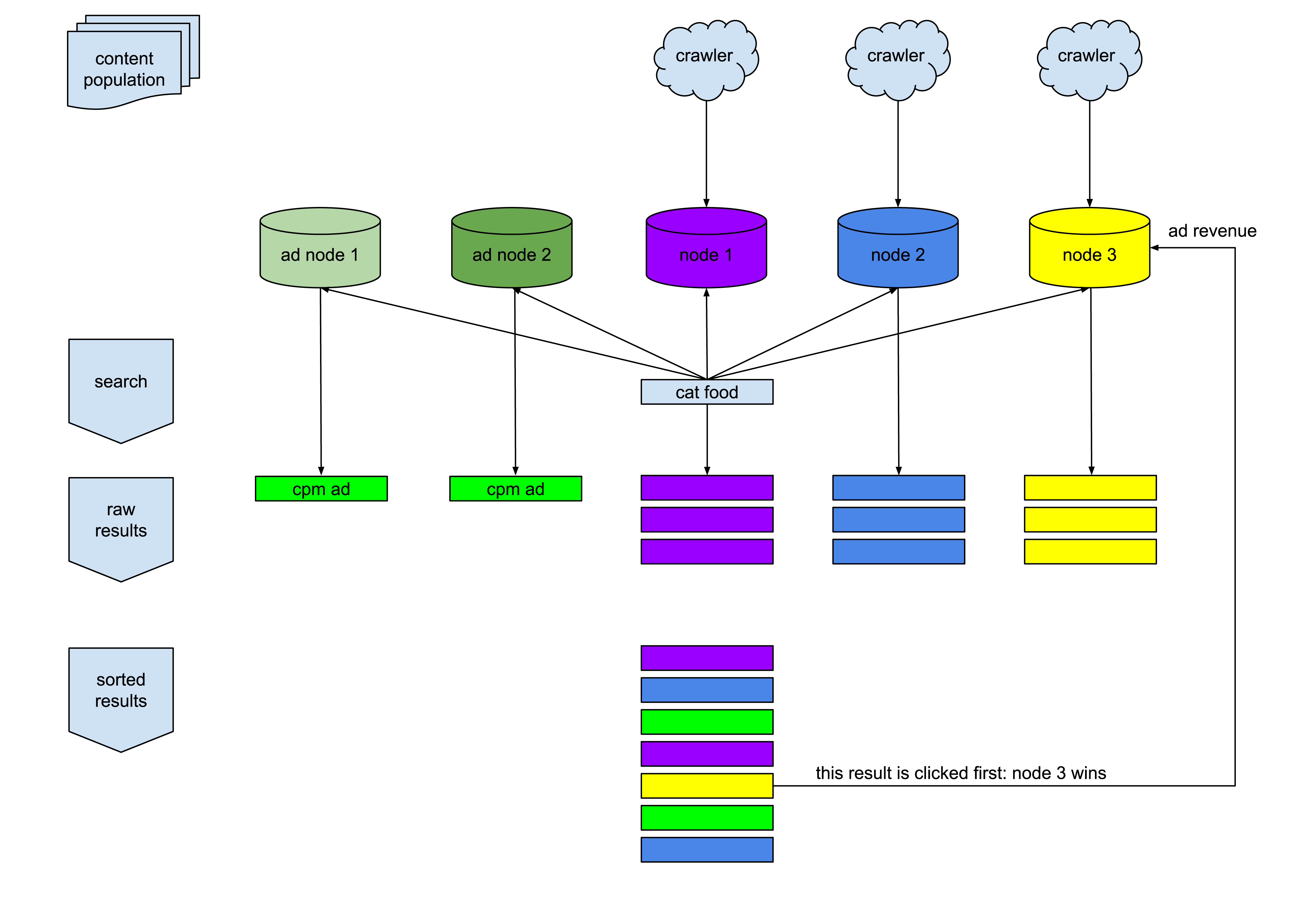
process summary
every user of the tangled browser (node) is eligible to participate in the tangled search network. each node crawls content from the internet and stores it in a local database. each local database contains a small fraction of the total amount of content on the internet. in addition, browser users can create ad campaigns in their local database, such as promoting products and services. each node is connected to a small number of peers, forming a large network.
when a user (searcher) submits a search for "cat food" to the tangled search engine, the search request is propagated to that user's peer nodes, and to those nodes' peers, etc. all the nodes that receive the search request do a search of their local database and return records to the searcher. some of the responses are advertisements that advertiser nodes have indicated to be related to "cat food". the advertisements are pay-per-impression.
when the search is complete, the searcher's machine sorts the results and ads based on the searcher's preferences. whichever search result they click first indicates the node that won the search. the network provides the advertiser with the millix address of the node that won the search, and payment is sent.
assumptions
each node is connected to 10 peer nodes.
a search request can be propagated to 10 peers within 100 milliseconds.
a search request expires 500 milliseconds after it is submitted, at which point propagation stops.
a search request can be propagated to up to 100,000 (10 to the fifth) nodes in 500 milliseconds.
traditional search engines at least double content data size with meta data representing relationships between records. tangled search does not store any intra-record metadata.
total number of pages on the internet: 6 billion.
Pareto's law implies the number of relevant pages on the internet (80/20): 1.2 billion.
average size of page content: 100 kilobytes.
total size of relevant content: 120 terabytes.
install base of tangled browser (node): 1 million.
theoretical disk space needed per node for complete coverage: 120 megabytes.
any disk space allocation in addition to 120 megabytes reduces reliance on install base and improves data availability and proximity to the searcher.
populating data to critical mass
prior to the search feature being publicly available, a collection of tangled nodes with large disks will begin crawling using a large pool of IP addresses in the tangled data center. each node is given a starting point to begin crawling. for example, one node will use the english version of the wikipedia home page as a start point to crawl content and populate links it discovers into its crawl queue. another node starts on the spanish version of the wikipedia home page. other nodes start on popular news sites, sports sites, celebrity sites, etc., and follow the links to new pages.
as tangled nodes come online and populate their local databases with the content they passively browse, the network data grows and the data that is populated is inherently targeted to the tangled demographic. content from sites that contain large amounts of data (dominant sites with classified ads, job listings, e-tailers) that block crawlers, will be gradually represented in the search network as the tangled install base and their correspondingly large pool of IP addresses is exposed to the content.
local database
tangled browsers passively populate their local content database as pages are viewed by the user and can actively populate by indicating a starting point to crawl.
crawl queue
a table is stored on each tangled browser node that is filled with links discovered on pages that have been viewed or processed. the links contained in the crawl queue are loaded and processed in the background. the crawl queue keeps track of how many times to retry a link before giving up.
local database population: passive mode (default)
each time a tangled user manually browses a page, it upserts their local database with the content of the page. when the content is upserted, the outbound links from that page are added to their crawl queue.
local database population: active mode (optional)
active database population begins by providing a URL that the browser uses as a starting point to crawl in the background. In this way, a tangled user can influence a niche of content for a topic or language.
search results
although each tangled browser populates their local database in their own way, the method by which search results are ordered is determined by the searcher. this means that if multiple nodes are presented with the same search phrase, and their database produces a different set of results in response to that query, the searcher will order the results based on their own preference. these preferences can include first known publish date, domain reputation, update date, cross links within results, etc. as long as basic, impartial facts about the data is stored in the local databases and provided in the responses, any filtering can be applied to the results by each user.
prefilter
as the search results are received and sorted on the searcher's machine, the browser attempts to detect malicious sites or content (expired ssl, scripts, excessive redirects etc).
node block list
each node maintains a list of nodes that have provided suspicious or malicious data. responses from these nodes are filtered out of the search results. the blocked nodes are not made aware of the block.
content verification
controls are needed to prevent node operators from stuffing their database with content that links to an unrelated site. the browser performs constant audits comparing the content presented in search results to the content actually on the page. since the crawler logic that populated the content exists on each browser, the browser viewing the content can apply the crawler logic to the content prior to displaying it to the searcher to determine if it is a close match (character count, link count, domains linked, keyword density, etc). this verification between page load and page display would take milliseconds. if it is not a close match a warning is displayed and the node can be added to the searchers node block list.
advertisers
the advertising marketplace operates in the same decentralized way that the search engine does. any tangled browser (node) user can create ad campaigns in their local database. those nodes announce themselves to the network as having active, funded ads available for specific keywords and regions. the advertisements are fetched from the network and blended into the search results presented to the searcher.
each active campaign has an associated millix address with a balance equal to their budget plus a buffer amount to cover in-progress searches after their budget is consumed. if the balance of the address is less than the buffer amount, the campaign is deactivated from network availability until it is replenished. each time a search is performed and a result is clicked, the advertisers that appear in the results would be instructed to send a payment to the node that won the search.
if the advertiser does not pay the advertising fee as expected, the reputation of the advertiser and potentially the domain featured in the ad, is negatively impacted. some amount of missed payments is accepted due to their node being offline or advertisement demand velocity exceeding the speed of deactivating the advertisement due to funding, but repeat offenders trying to game the system need to be visible to the network and avoided.
economics
search results come from multiple peer nodes. advertisements related to the search term are provided from nodes running ad campaigns. the search results and the ads are blended together locally on the searcher's device. the advertising revenue is primarily paid to the peer node that provided the search result record that was selected by the user. the response time of the peer is the tie breaker. whichever peer provided the results to the searcher first wins a tie. the race condition incentivizes tangled nodes to have the most powerful computer hosting the largest, most current databases filled with the most searched content, running on the fastest networks, connected to the most peers.
fraud
comprehensive fraud detection is a significant cost for traditional search engines and advertising platforms. the tangled search network can't approach fraud using the same perspective that traditional platforms do. the tangled search network uses economic friction, low overhead expenses and low advertising cost models to make fraud unattractive and the existence of fraud palatable to advertisers.
fraud vectors
bad actors can attempt to game the system by flooding their database with spam results in an attempt to match every search.
bad actors can populate their database with niche content, then conduct searches for that content with little or no competition.
bad actors can modify their search result sorting to favor the content in their own database and earn advertising revenue for their own searches.
economic friction
a limited number of searches per hour are permitted with no cost. beyond that limit, the searcher must pay a fee for each search to make it economically unattractive to direct advertiser payments to themself. the fee cannot be paid directly to the nodes producing results without the possibility that a node pays a fee to itself and bypasses the intended friction. search fees are paid to a tangled search network address to fund development and to stimulate the economy.
in summary, fraud is expected and a best effort attempt is made to reduce it without incurring the costs required to eliminate it.
advertising model
initially, advertising campaigns are pay-per-impression, not pay-per-click. as pay-per-impression has a lower unit cost than per click, advertisers can begin participating in the advertising platform with lower risk. bad advertisers that don't pay are identified quickly, without great financial loss to nodes.
it is understood by the advertiser that pay-per-impression ads have a smaller likelihood of costly action by the end user than pay-per-click. pay-per-impression rates may be 100x lower than than pay-per-click. as a result, 100x the fraudulent actions must be performed in a pay-per-impression model than would be necessary with pay-per-click, making the fraud that much easier to detect.
the pay-per-impression model also lends itself to fewer types of optimizations which lowers the development cost of adapting it to a decentralized model.
a minimum rate will be enforced by the network (i.e. $1 per 1,000 impressions) and each advertiser can increase their bid in combination with targeting. when the ads are provided to the searcher, their device sorts the ads by bid.
if a search result is clicked by the searcher, all the advertisers that appeared are instructed to pay their bid amount to the node that provided the winning result. the advertisers respond to the searcher with a valid transaction identifier representing the payment. if an invalid, or no transaction id is provided, the advertiser is blocked by the searcher node for a period of time. if no search result is clicked, the advertisers are instructed to pay a tangled search network address to fund development and stimulate the economy.
advertisement campaigns that are available to tangled search are also eligible for the tangled browser header ad space and tangled social pages.
search propagation
by setting an expiration timestamp on each search submittal, the network knows when to stop propagating the search request to more nodes. if the expiration timestamp is 500 milliseconds from now, the search request will continue to be forwarded from node to node until the current time is greater than the search expiration time. this manages the number of nodes that are loaded down by the search.
each node that has received the request will query its database and respond to the searcher.
overview
for every hour that a user is active, a stimulus payment is sent from the tangled system to the user. the payment is intended to cover the cost of normal levels of engagement with content and posting content. the size of the stimulus payments acts as a throttle (spam deterrent) on how frequently a user can post content until the community assigns a value to the user's content through engagement earnings. using the tangled browser increases the size of the stimulus payments.
this feature serves as legal protection for tangled users within the United States legal jurisdiction and for the tangled team. the data requested from, and contained in, the tangled database is open and readable by anyone participating on the network. law enforcement agencies conducting investigations can access the contents of the search engine network in the same way individual users can. the tangled team has no additional data beyond what is made available on the network.
this functionality is used as a response to content specifically referenced in legal filings, court orders and law enforcement actions and for content that has not triggered legal action but that clearly would in the view of our legal team. in recognition of the nature of this tool, complete transparency is provided when data is added to the block list. the history of urls being blocked is available on each tangled browser node for any user or agency to inspect and audit.
these are the components used by the content purge and block feature:
centralized key
the tangled team posses a cryptographic key used to add records to the purge and block list.
purge and block list subscription
each page in the tangled network has an associated url. each page is identified with a unique identifier. once that identifier exists in the user's tangled search database, it cannot be re-inserted. nodes subscribing to this feature periodically pull the block list from the tangled team. this feature is enabled in the tangled search configurations by default; users can opt out of the content block list subscription at their own risk.
content expiration
the larger the tangled search network is, the faster content can be expired: requiring page re-examination and re-populatation. the perspective of the tangled team is that it is the obligation of law enforcement agencies around the world to take down illegal content and redirect violating domain names within their jurisdiction to agency landing pages. by expiring the content in the tangled search database quickly, these law enforcement actions are recognized by the tangled search network quickly, causing the illegal content to be replaced with the content of the agency landing pages.
this represents a best effort policy to keep all the content stored within the tangled network in compliance with all vigilant law enforcement agencies around the world.
mature & sensitive content
the tangled search system accesses and stores text content from web pages by following links. it is impossible to anticipate what content exists on a page prior to requesting the page. this can cause tangled users' devices to wander down dark alleys of the internet. the text content discovered on pages is stored locally on the user's device. the content that is stored is not encrypted; doing so makes content searches effectively impossible. tangled users operating in jurisdictions known to punish people for accessing content that is easily found on the internet should not participate in active crawls.
although the tangled search software makes superficial efforts to categorize content and identify mature & sensitive content, its ability to categorize or identify content should not be relied upon when the consequences of its inadequacy are a punishable offense for the tangled user.
crawler
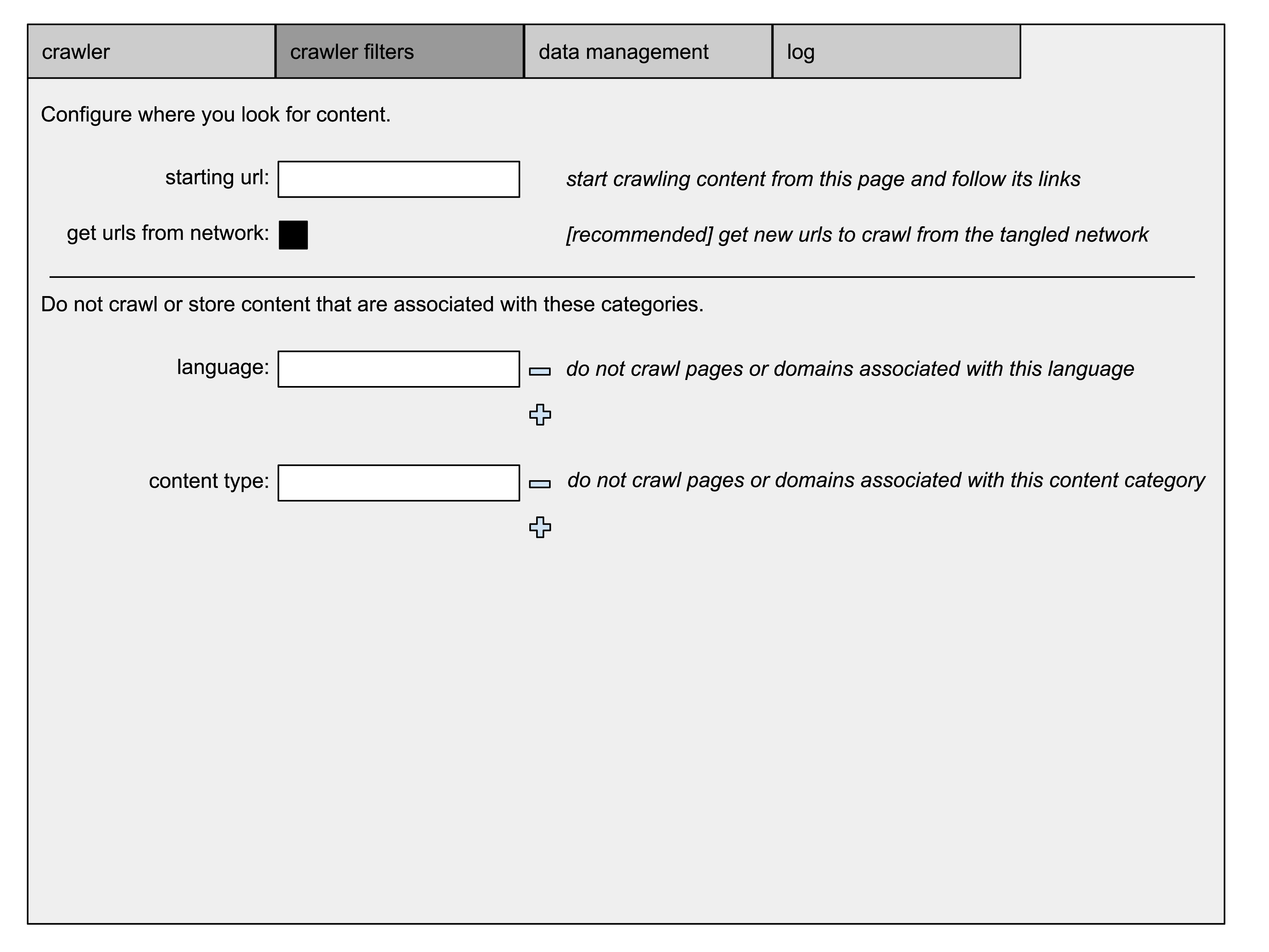
the tangled browser allows its user to configure it's crawl behavior with thread count, crawl throttle, backoff time, reattempt count, and disk allocation. these configurations apply to passive and active crawl modes.
in addition, the user can configure crawl filters based on domain or page attributes (i.e. mature, language). these crawl filters should not be relied upon by users operating in jurisdictions known to punish people for accessing content that is easily found on the internet.
the tangled browser allows its user to configure a url as a starting point to crawl. this only applies when the crawler is in active crawl mode. if no starting point is configured, or the node has no pending links to crawl or all the pending links / domains are blocking the node, the node makes a request for links pending crawl from the network. the links returned by the network are unfiltered. the node determines which records to add to it's queue based on its preferences and filters.
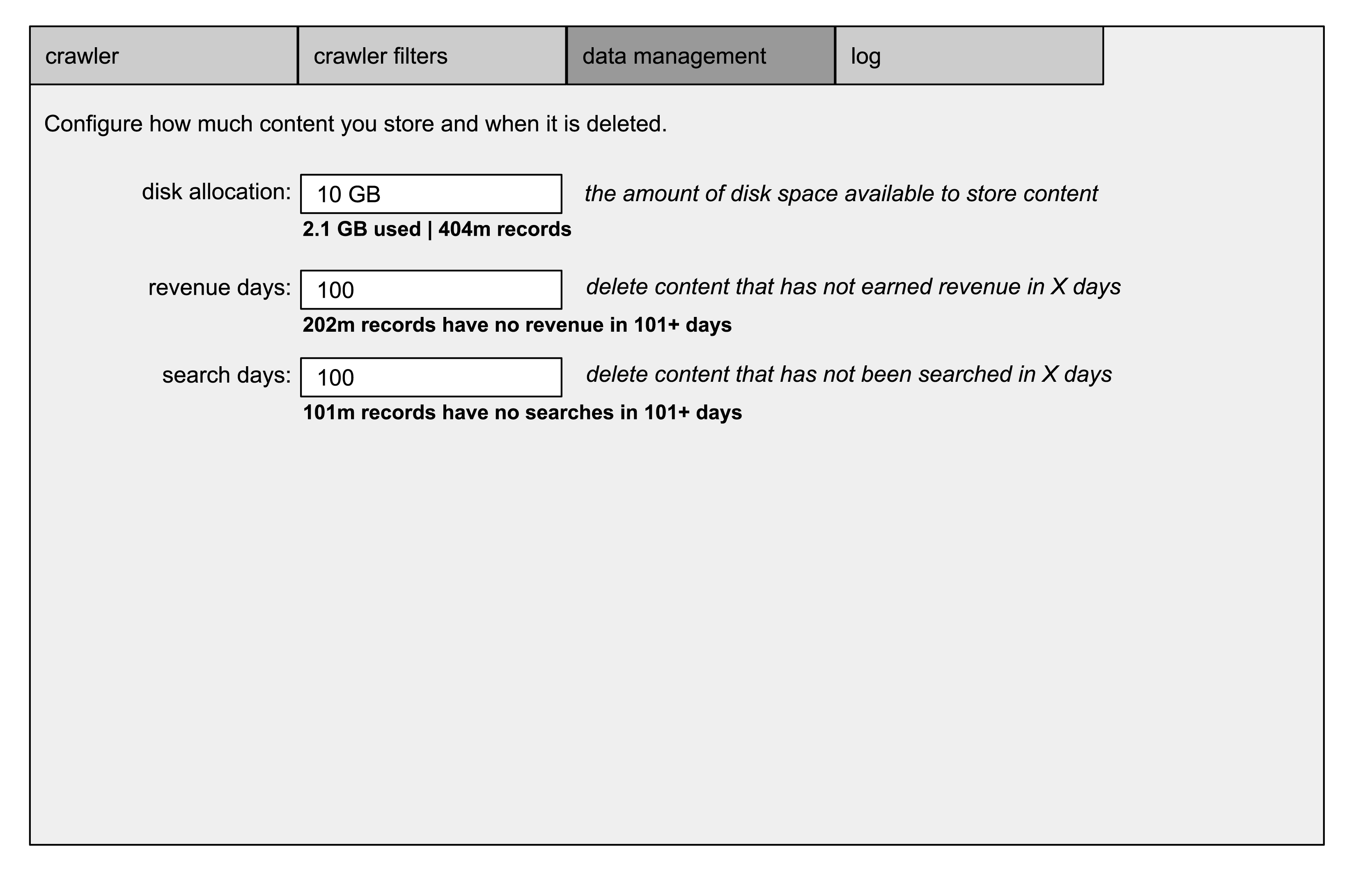
the tangled browser has record management configurations that allow it to prune data that hasn't been requested or that hasn't earned revenue in a certain time period. it can also prune page records that don't have adequate %_count values.

content processing
prior to pinging a link, the URL is compared with crawler filter settings to determine whether to continue. when the link is requested, a timer begins to measure page load time.
content that is retrieved from the crawler is processed for metadata, denormalization, indexing and efficiency. the following steps are performed in memory:
parse header data, page title, domain data
-
determine whether page self identifies as mature
<meta name="rating" content="adult" />
<meta name="rating" content="RTA-5042-1996-1400-1577-RTA" />
if content is allowed by crawler filter then continue
-
determine whether page self identifies language
lang="en"
<meta http-equiv="Content-Type" content="...; charset=..." />
<meta charset="..." >
if content is allowed by crawler filter then continue
-
determine whether page is responsive for mobile devices
<meta name="viewport" content="...">
-
determine whether page self identifies as a redirect
<meta http-equiv="refresh" content="...;url=..." />
parse meta counts (bytes, images, links, errors, warnings, cookies, forms etc)
determine whether malicious scripts exists
parse outbound links
remove html
remove scripts
remove punctuation, irrelevant grammar (quantifiers, articles, intensifiers, conjunctions)
produce key word density
determine whether mature content exists in keyword density
if content is allowed by crawler filter then continue
parse geography using host IP address (database), postal addresses (no database)
upsert records to database.
search requests
the following fields are submitted to the network to perform a search.
search_guid
node ip_address
node latitude,
node longitude
search phrase
synonym array
element type (web, image, video, product)
allow_sponsor (determines whether ads are allowed in the results)
expiration (timestamp at which point the request stops propagating and responses are no longer accepted)
record_limit (per node)
fee
search request propagation and search response
the nodes that receive the search request immediately forward the search request to their peers until the search expiration. simultaneous to search request propagation, the nodes queries their database for matches to the search phrase. if the node is configured to allow synonym phrase searches, it performs those database queries. if the node is configured as an advertiser and the search allows ads, the node queries its ad campaigns based on keywords, location and language.
as soon as the first response is received, the searcher sees a counter incrementing the number of nodes and results that have been received. when the search expiration time has passed, plus some time for network latency for the final responders, the searcher node indicates that it is processing the results. Then, the sorted results and ads are presented to the searcher.
ad search
simultaneous to the nodes responding to the search request, if allow_sponsor is enabled for the search, a request is made to sponsor nodes to provide advertisements targeted to the search.
search result
the search responses are processed locally by the searcher to determine the order of the search results. the searcher has a bias package (which can be shared from the community) that is applied to the responses.
when the search response expiration has passed, no further responses are accepted and the searcher processes the responses into results.
in addition to using the count fields, phrase relevance and synonym relevance to sort the responses, the response_page_link arrays are used to determine if any of the pages link to other pages in the collective response list.
for example, if pages 1 and 2 contain links to page 3, then page 3 is a candidate for subject matter authority.
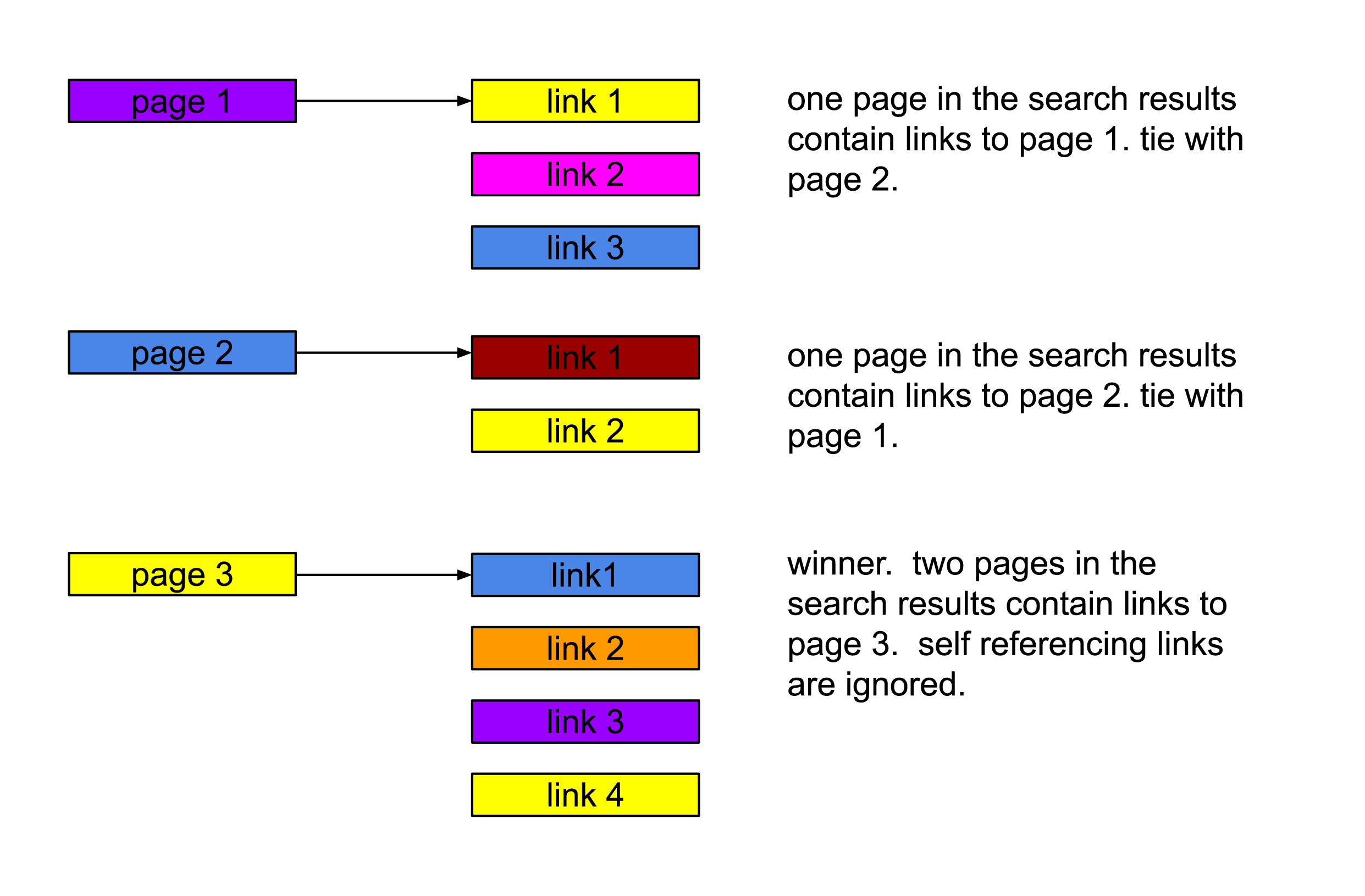
search settlement
search settlement closes the search with payments. when the search results appear on the searchers page, all the data exists on the searcher's device to perform the search settlement. there are a number of scenarios:
search did not allow ads
if the search request disallowed ads then the searcher paid a fee.
searcher paid fee
if the searcher paid a fee due to disallow ads, extend the search expiration, increase the record limit per node or to support the tangled network, the fee is paid from the searcher to a tangled network address to fund development and stimulate the economy
ads were provided to searcher
when ads are provided to the searcher to be merged with the search results, they are accompanied with a bid amount for the impression. if the ad appears on the searcher's screen (depending on the location of the page fold and the order of the ads), the advertiser is obligated to pay for the impression. the only question is who the payment is made to, which is answered in the final two scenarios.
searcher selects a search result
if the searcher selects one of the results provided by a node, that node is owed payment from all the advertisers who have appeared to the searcher on that list of results. the searcher sends a message to the advertisers with instructions to pay the node that won. the message indicates the search_guid, amount, node_guid and millix address of the node to pay. the advertising node verifies that it participated in the search_guid, verifies that it has not already made payment related to the search_guid, sends the payment to the address provided and updates it's database for reporting. the advertising nodes respond to the searcher with a transaction id for the payment.
this process can repeat if the searcher views and engages with multiple pages of search results.
searcher does not select any search results
if the searcher leaves the search results or does not select any search results in a given time period, the tangled browser determines that the search was unsuccessful. even though the search was unsuccessful for the searcher, the advertisers still benefited from their ads being seen by the searcher. since there is no node to make the payment to based on search results, the browser instructs the advertising nodes to send payment to a tangled network address to fund development and stimulate the economy with the goal of improving the network, improving the search results and decreasing the rate of failed searches.
if no valid transaction id is provided from an advertising node, it's reputation is affected. the reputation of the advertiser node can cause nodes to block ads from the advertising node in subsequent searches.
network meta data
by operating a large number of nodes connected to a large number of peers, tangled.com has visibility to searches propagating through the network and can report on trends. this ability is not restricted to tangled.com, anyone connected to the network can analyze the behavior of the network.
in addition, tangled.com has visibility to search settlement data observed by the browser software. this data can be analyzed to publish reports on economic and advertising metrics. all data gathered by tangled.com will be publicly available in aggregate.